Item level treatment effect heterogeneity
Peter F Halpin & James Eagle
2026-04-23
Testing for impact.RmdDifferential item functioning
In the Item Response Theory (IRT) literature, Differential Item Functioning (DIF) is an approach to assessing situations where response values to an assessment differ as a function of an external covariate (for example, gender or treatment condition). In many contexts, the main goal of DIF analysis is to evaluate whether the items on an assessment are biased in regards to these external covariates. In treatment vs control studies, DIF/bias due to treatment condition can be problematic because it can lead to the over-inflation of the treatment effect and limit generalizability to other assessments.
The following example demonstrates how to use robustDIF
to investigate DIF and potential impact of treatment condition (the
treatment effect) on a set of mathematical achievement items.
Effect of an Adaptive Game-Based Math Learning App on Students’ Learning
In a recent block randomized control trial, Bang, Li, and Flynn (2022) investigated whether using My Math Academy, a personalized adaptive learning app, could improve math achievement and learning engagement in K-1 students (n=505 treatment, n=481 control). My Math Academy supplemented school curricula with game-based activities, performance dashboards for teachers, and offline additional learning activities.
Blocking on school and grade, teachers were cluster randomized to treatment (21 classrooms) or control (20 classrooms). Treatment teachers were tasked with using My Math Academy for at least 60 minutes per week. Control teachers implemented whatever math curricula the district used. The intervention took place between February and June 2019. In total, 41 classrooms from 11 elementary schools participated.
Math achievement was measured at pre-test and post-test using 38 multiple-choice items selected from the Certica assessment item bank. Items were selected if they aligned with Common Core State Standards for K-2 and targeted specific My Math Academy learning objectives. Students had 30-45 minutes to complete the assessment. Responses were coded as 0 (incorrect) or 1 (correct) for the analyses.
Bang and colleagues (2022) estimated a simple treatment effect by computing the difference between mean un-weighted post-test total scores:
Dividing by the pooled standard deviation gives a measure of effect size (d):
These findings indicate students using My Math Academy had greater math achievement scores than students who did not, but the difference is relatively small. The following analysis will examine whether this effect size is robust to item-level sources of variability that may not generalize to other measures of Math achievement (i.e., tests that have different questions).
Step 1: Fit IRT model to data
To begin the procedure, we will need to fit an IRT model to the data. All data used in this example is available from the Item Response Warehouse (https://itemresponsewarehouse.org/) and can be downloaded using the following code:
library(irw) # You may need to first install the package with `devtools::install_github("itemresponsewarehouse/Rpkg")`
# On first use, you will need to log in with a Redivis account (a platform for academic data sharing). See instructions for this on the IRW website.
# Pull the selected data-set
irw.data <- irw_fetch("gilbert_meta_23")
# Pivot to wide format
wide <- irw_long2resp(irw.data)
# Add cluster ID and treatment ID to wide data
data <- left_join(wide, irw.data[,c(1,2,7)], by="id",multiple="first")The following code utilizes mirt to build 2PL IRT models
for future testing of robustDIF:
library(mirt) # You may need to install the package first with install.packages("mirt")
# Subset data to just test items
items <- data[,-c(1,40,41)]
# Calculate 1-factor 2PL models, using treatment to split groups and specifying SE=TRUE for the covariance matrix.
mirt.dat <- multipleGroup(items,
model = 1,
group= as.factor(data$treat),
itemtype = "2PL",
SE=TRUE)
# Plot the IRFs
plot(mirt.dat, type = "trace", facet = F)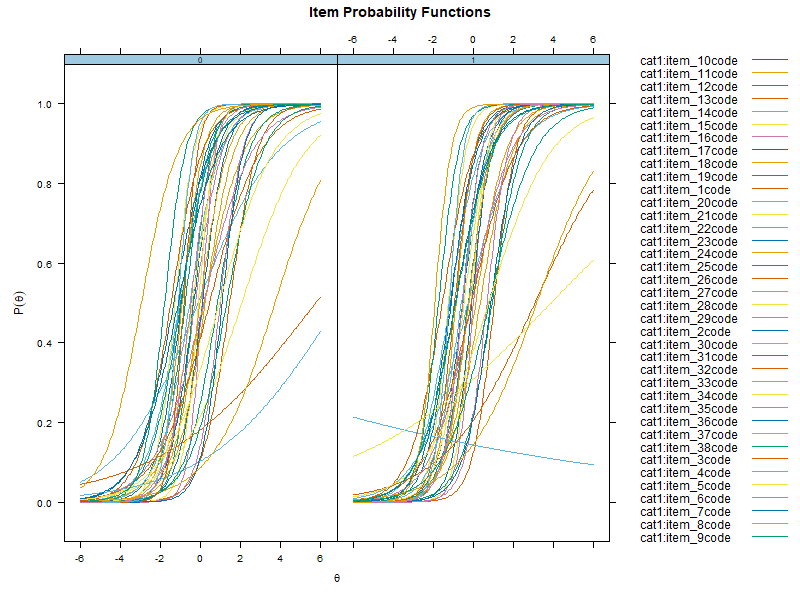
A useful first step is to investigate the item response functions
(IRFs) of the multiple group 2PL model using plot().
Essentially, we are looking for similarities and differences between
response functions in the treatment (1) and control (0) groups. If the
response functions look near identical, we may not expect to uncover any
DIF.
When fitting 2PL IRT models, the latent trait
(representing children’s underlying “math ability”) needs to be scaled
(i.e., we restrain it to have a mean of zero and variance of one). This
can be problematic when testing differences between groups (tests of
DIF), because if we arbitrarily scale
in both groups, we give their
the same mean and variance. In other words, we end up removing any
differences and will show zero impact. The robustDIF
procedure tackles this problem by instead using robust statistics to
estimate scaling parameters and flag items for DIF.
A second issue here is the clustering of observations: students
within the same classroom may have similar characteristics (e.g., have
similar capabilities, backgrounds, etc.). This leads to partial
redundancies in their scores which should be accounted for. The
robustDIF package can handle this by specifying a
cluster variable (e.g., classroom id’s) in the
get_model_parms() function.
Step 2: Is the overall treatment effect robust to item-level variability?
Children using My Math Academy may be exposed to certain types of questions more frequently than those in the control group. For example, My Math Academy includes games that use base-ten blocks for addition and subtraction, whereas some control curricula may not. If the post-test assessment includes base-ten block items, then score differences between groups on those items could reflect differential exposure rather than true differences in underlying math ability.
This issue is known as “construct-irrelevant item-level heterogenous treatment effects” (construct-irrelevant IL-HTE, or construct-irrelevant DIF) and would cast doubt on using total scores, which include base-ten block questions, as a way of demonstrating that the treatment improved math ability.
Additionally, if IL-HTE is present, the generalizability of the treatment effect might be questioned. If the treatment effect is driven by only a subset of test questions, then tests with different questions may not show the same magnitude of effect.
We will turn next to demonstrating how to test for IL-HTE.
The get_model_parms() function from
robustDIF can be used to extract item-level estimates from
the mirt object. After, robustness to item-level
variability can be investigated using the rdif() function.
Users supply a significance level by setting alpha (here,
.05) and testing for DIF on slope (discrimination),
intercept (difficulty), or both with fun.
Here, we choose d_fun1 to test whether the treatment
effect computed using the un-weighted mean of items and scaled to the
control group is robust to item-level sources of variation.
# Extract cluster indicator variables (classroom/teacher id)
group_vars <- data$cluster_id
# Save model parameters
parms <- get_model_parms(mirt.dat, cluster = group_vars)
# Investigate DIF
mod <- rdif(mle = parms, fun = "d_fun1", alpha = .05)
# Print estimate
print(mod)## Est: 0.1041982 SE: 0.2798387The print() function provides the robust treatment
effect estimate (0.10) and standard error
(0.28) estimated using iteratively reweighted least squares
with Tukey’s bisquare.
The delta_test() function provides both a naive effect
estimate (one that aggregates over all test items) and a robust estimate
that adjusts for item-level variation.
delta_test(mod)## naive.est naive.se rdif.est rdif.se delta delta.se z.test p.val
## 1 0.2449639 0.307209 0.1041982 0.2798387 0.1407657 0.06516024 2.1603 0.03074946The naive effect estimate is 0.24,
SE = 0.31. The robust effect estimate that adjusts for
item-level variation is 0.10, SE = 0.28. This
significant difference (p < 0.05) implies that the
treatment effect on the total score was driven by only a subset of items
with relatively large effects. These items will be investigated
next.
Step 3: Which items show differential treatment effects?
Using summary will provide deltas (the
estimated scaling parameter subtracted from the item-level scaling
function value) and p-valuesfor each item. Significant
p-values indicate that, at the chosen alpha,
the item was flagged for DIF. Those items are down-weighted to zero
during estimation of the scaling parameter.
# Print summary
summary(mod)## Robust Scaling and Differential Item Functioning.
##
## Data: 38 items
## Estimation ended after 13 iterations
## Single solution found
##
## Est: 0.104 SE: 0.2798
##
## Results from Wald Tests of DIF:
## delta se z.test p.val
## item1_d1 0.115633003 0.19682025 0.58750563 0.556864172
## item2_d1 -0.066612378 0.18127570 -0.36746446 0.713272597
## item3_d1 -0.190324096 0.16870574 -1.12814241 0.259259781
## item4_d1 0.020063711 0.23962197 0.08373068 0.933270562
## item5_d1 0.055510667 0.16768000 0.33105121 0.740605807
## item6_d1 -0.021597174 0.21032340 -0.10268555 0.918212541
## item7_d1 -0.084641477 0.17648935 -0.47958405 0.631523192
## item8_d1 0.108560507 0.14782891 0.73436589 0.462725771
## item9_d1 -0.006712899 0.15449566 -0.04345041 0.965342495
## item10_d1 -0.275029789 0.11388624 -2.41495183 0.015737291
## item11_d1 -0.063338260 0.17209726 -0.36803758 0.712845211
## item12_d1 0.222371903 0.36177041 0.61467687 0.538768138
## item13_d1 -0.092438955 0.10352617 -0.89290427 0.371908439
## item14_d1 -0.032820851 0.08948296 -0.36678326 0.713780694
## item15_d1 0.092338815 0.13099809 0.70488672 0.480880735
## item16_d1 -0.159438851 0.12119595 -1.31554602 0.188326462
## item17_d1 -0.210254838 0.16900943 -1.24404204 0.213484089
## item18_d1 0.489239880 0.82998800 0.58945416 0.555556652
## item19_d1 0.055374051 0.17508307 0.31627302 0.751795291
## item20_d1 -0.009162725 0.13975430 -0.06556310 0.947725668
## item21_d1 0.192334938 0.31953693 0.60191771 0.547228913
## item22_d1 0.156423564 0.19457760 0.80391354 0.421446908
## item23_d1 0.165641941 0.13784953 1.20161411 0.229513074
## item24_d1 -0.084950693 0.30150778 -0.28175291 0.778132982
## item25_d1 0.465575917 0.28297684 1.64527926 0.099912235
## item26_d1 1.109023313 0.75694377 1.46513302 0.142884629
## item27_d1 0.678945204 0.28757927 2.36089760 0.018230764
## item28_d1 0.194769667 0.16581094 1.17464905 0.240135152
## item29_d1 0.303730038 0.12956905 2.34415578 0.019070204
## item30_d1 0.824750765 0.42354780 1.94724365 0.051505531
## item31_d1 0.578251407 0.19174741 3.01569344 0.002563923
## item32_d1 -0.288450618 0.17646126 -1.63463990 0.102124557
## item33_d1 0.047250317 0.35604143 0.13271016 0.894422604
## item34_d1 0.176916512 0.20866159 0.84786335 0.396514080
## item35_d1 0.053548904 0.14845794 0.36070085 0.718323092
## item36_d1 -0.168924579 0.25620832 -0.65932510 0.509687027
## item37_d1 1.329555051 0.83878924 1.58508835 0.112946263
## item38_d1 -0.332016808 0.17156521 -1.93522224 0.052963029The direction and magnitude of the significant item-level effects
reveal which items were increasing or decreasing the treatment effect.
We can subset to significant (p-value < alpha) items and
plot their effects and 95% CI’s in relation to the robust estimate to
visualize this.
# Subset to significant items (set your own p-value if different from 0.05)
sig.items <- mod[["dif.test"]][mod[["dif.test"]]$p.val < 0.05, ]
# Save robust estimate
rob.est <- mod[["est"]]
# Plot
library(ggplot2) # You may need to install the package first with install.packages("ggplot2")
p <- ggplot(data = sig.items, aes(x = row.names(sig.items), y = delta)) +
geom_point() +
geom_errorbar(aes(ymin = delta - 1.96*se, ymax = delta + 1.96*se), width=0.1) +
geom_hline(yintercept=rob.est, col="red", lwd=1) +
labs(x = "Item", y = "Delta", title = "Item-level Treatment Effects")
p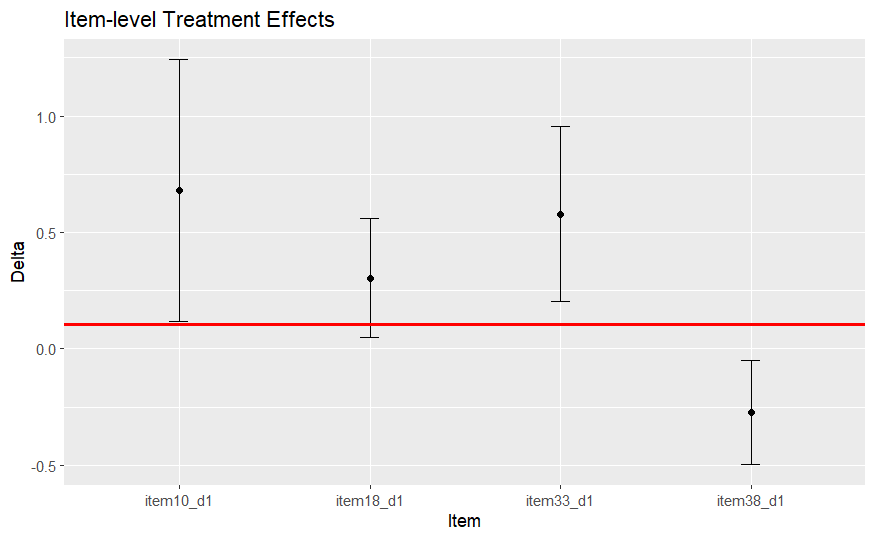
Items whose 95% CIs do not cross the red line had item-level effects significantly larger or smaller than the robust treatment effect estimate. These items were:
Question 10: (“A group of circles is shown. Which of these groups represents the same number of circles?”)
Question 33: (Using base-ten blocks: “What is 355 - 262?”)
Question 38: (“98 - 36 =”)
Items 10 and 33 had positive item-level effect deltas, biasing the treatment effect upward. Only item 38 had a negative item-level effect delta, biasing the treatment effect down. These results indicate that the upward bias of the naive treatment effect was being driven by only two items. If students using My Math Academy had more exposure to these two question types (using circles and base-ten blocks), then the construct validity of the naive treatment effect using total scores would be threatened. In other words, the total scores may not accurately capture math ability. Additionally, the naive effect may be smaller in studies using tests without these two items.
Step 4: Sensitivity analysis
Before proceeding with the analysis and making inferences about
DIF/IL-HTE, use plot() to visually inspect the Rho Function
for a clear global minimum.
# Plot Rho Function
plot(mod)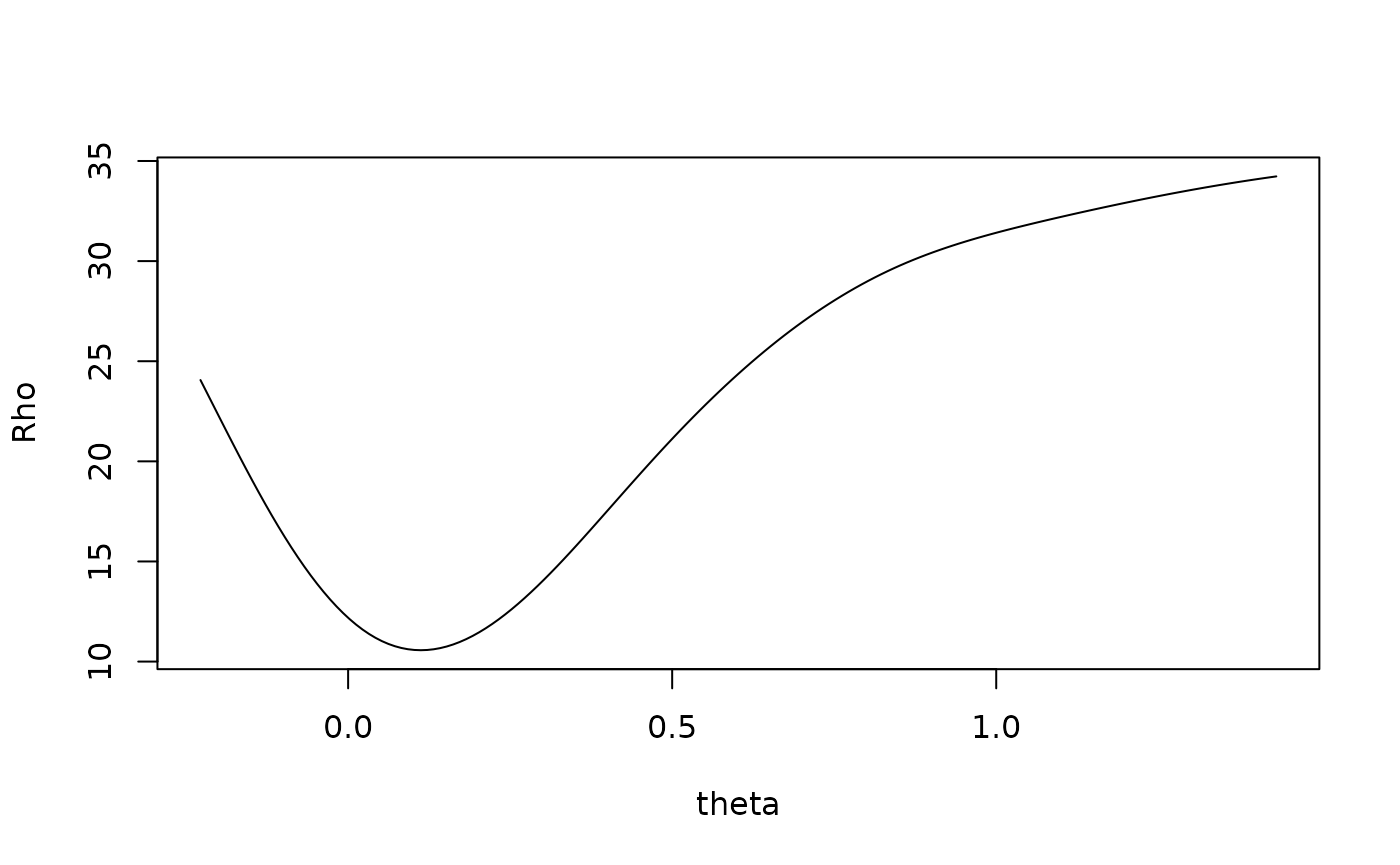
Here, the Rho Function has a clear global minimum, indicating there is a single solution for the scaling parameter. If the Rho function showed multiple local minima of similar values, there would potentially be multiple solutions, and the results would be sensitive to which minima was used during calculations.
Step 5: Conclusion
In the absence of IL-HTE, the treatment effect based on the total test score and the treatment effect on underlying math ability is equivalent. When IL-HTE is present, as in this example, we can conclude the two are not: comparing mean total scores between groups may not be an adequate representation of differences in underlying math ability.
Researchers in this situation have several options to address these concerns. The first would be to provide evidence that My Math Academy students did not have more exposure to these question types than control students. Assuming this is true, then researchers might caution readers that the results were largely driven by a few items, or conduct a sensitivity analysis by replacing biased assessment items on a follow-up sample and comparing effect magnitudes between tests.